rust编译器初探:Rust编译器是如何工作的
阅读本篇博客需要了解编译原理相关知识,比如词法分析、语法分析、语义分析、代码生成等。
阅读本篇博客需要有一定的Rust语言基础,比如知道lifetime, ownership, borrow等概念。
这篇博客主要学习记录Rust程序编译的整个流程。一般的编译过程分为词法分析、语法分析、语义分析、代码生成这些步骤,Rust的编译器也逃脱不了这个框架。Rust编译器特殊的地方在于:(1)由于Rust引入了新的类型系统(ownership, borrow等),Rust编译器还需要做一些额外的检查(比如,borrow checking)。(2)为了实现demand-driven compilation,Rust编译器定义了一个特殊的查询系统(query system)。
Overview
下图展示了编译Rust程序的主要步骤:
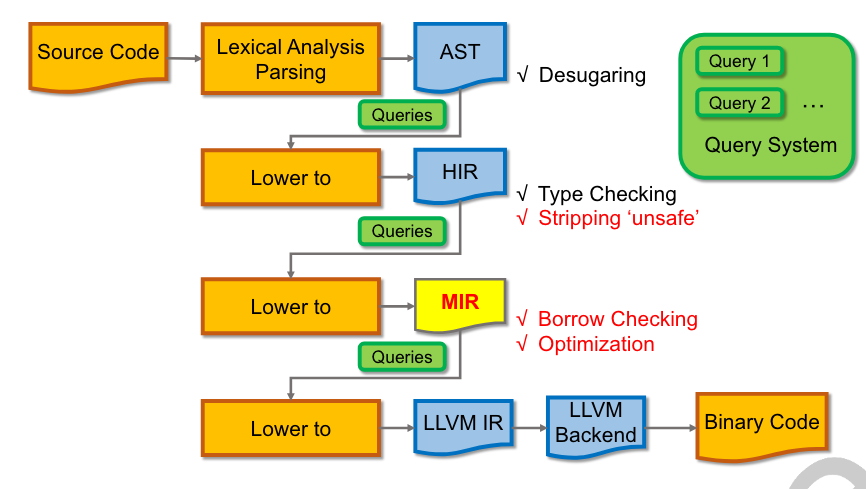
1. 词法分析 (Lexing)
Lexer把源码转化为一个个tokens。
2. 语法分析 (Parsing)
AST
Parser把tokens转化为抽象语法树(AST)。
HIR
接着,AST会被转化成为HIR(High-level intermediate representation)。HIR是一种对编译器更加友好的 AST 表示,在AST到HIR的转化过程中会进行:
-
macro expansion
-
desugar语法糖,比如
for n in num类似的语法糖会被展开成match和loop来看一个例子,对以下代码:
fn main(){ let numbers = vec![1,2,3,4,5]; for n in numbers { println!("{}", n) } }我们关注
for n in numbers这个循环,这个语法糖会被desugar为:let result = match IntoIterator::into_iter(numbers) { mut iter => loop { let next; match iter.next() { Some(val) => next = val, None => break, }; (...) }, } -
resolve imports
unsafe的代码块信息在HIR中还没有被删除。
HIR的数据结构表示如下:
-
Node: 一个node对应一个代码片段,每一个node都有一个HirId,并且属于一个definition
- Definition: an item in the crate we are compiling. These are primarily top level items within the crate. This is identified by a DefId, and a definition is owned by a crate.
- Crate: It stores the contents of the crate we are compiling and contains a number of maps and other things that help organize the content for easier access throughout the compilation process. This crate is identified with a CrateNum.

MIR
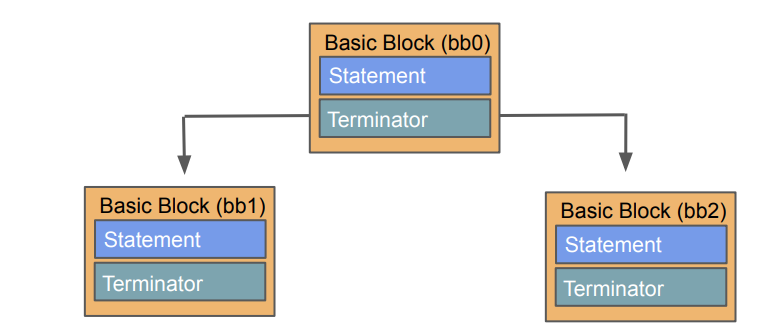
最后,HIR会被转化为MIR(Mid-level intermediate representation)。MIR说白了就是一张控制流图(control flow graph),basic block(bb)组成MIR的基本单元,每一个basic block中包含顺序执行的statement,basic block中最后一个statement被称为terminator。
statement主要由三种形式组成: Assignment, StorageLive和StorageDead
- Assignment: 把RValue赋值给LValue,赋值方式有mov, &, *等
- StorageLive: where a variable’s storage comes into existence,用来表示变量生命周期的开始
- StorageDead: where a variable’s storage goes out of existence,用来表示变量生命周期的结束
MIR中的syntax如下:

下面这段代码对应的MIR如下:
if condition {
do_one_thing
} else {
do_something_else
}
在这个HIR–MIR lowering过程中,一个more desugared HIR–THIR(Typed HIR)也会被构建出来。Rust 代码是单态化的(monomorphized),换句话说,就是编译器需要用具体类型替换generic中的类型参数,生成每一个具体类型所对应的代码。为此,我们需要收集一个列表,列出要生成代码的具体类型。这被称为单形态化收集,发生在 MIR 层。
3. 语义分析 (Semantic Analysis)
这个阶段,编译器会做很多轮的检查。
AST中会进行syntactic sanity checking,比如检查用户编写的类型是否是预期类型。
HIR用于类型推断(type inference), trait solving(将 impl 与每个对特征的引用配对的过程)以及类型检查(type checking)。类型检查是将用户编写的类型信息(在编译器中表示为hir::Ty)转化为编译器内部的类型表示(rustc_middle::ty::Ty<'tcx>)。
THIR用于patterning和exhaustiveness checking。
MIR用于borrow checking的分析和其他基于数据流的检查(dataflow-based checks),比如检查未初始化的值。
borrow checking会检查的内容有:
- Tracking initializations and moves
- Lifetime inference
- If you make a reference to a value, the lifetime of that reference cannot outlive the scope of the value
- drop check
4. Optimiaztion & Code generation
MIR是high-level and generic的中间代码表示,还没有被单态化,所以在MIR上做优化会比LLVM IR上高效很多。
代码生成阶段是将源代码的更高级别表示转换为可执行二进制文件的阶段。在代码生成的过程中,编译器首先将MIR转化成为LLVM IR,这个阶段中MIR真正被monomorphized。LLVM IR会接着被喂给LLVM,LLVM会对LLVM IR再做一些优化,并生成机器码。
Queries
Rust编译器通过使用query system来完成增量编译(incremental compilation),即如果用户对其程序进行更改并重新编译,编译器希望尽量减少不必要的工作量,以生成新的二进制文件。
在Rust编译器(rustc)中,编译的主要步骤都被组织成一组互相调用的queries。比如,有一个query用于获取某个东西的类型,另一个用于获取某个函数的MIR。这些查询可以相互调用,并且都通过查询系统进行跟踪。查询的结果被缓存到磁盘上,以便我们可以确定哪些查询的结果与上次编译不同,只重新执行那些查询。这就是增量编译的工作原理。
Reference
-
Preliminaries Section of “SafeDrop: Detecting Memory Deallocation Bugs of Rust Programs via Static Data-Flow Analysis”
Enjoy Reading This Article?
Here are some more articles you might like to read next: